| Prev | Next |
Would the tests described so far also run with content that is not ISO-8859-1, for example with Russian, Greek or Chinese text?
A difficult question. A lot of internal tests are done with Greek, Russian and Chinese documents, but tests are missing for Hebrew and Japanese documents. All in all it is not 100% clear that every available test will work with every language, but it should.
When you need to process Unicode data, it is good practice to configure all your tools to UTF-8.
The following hints may solve problems not only when working with UTF-8 files under PDFUnit. They may also be helpful in other situations.
Metadata and keywords can contain Unicode characters.
If your operating system does not support fonts for foreign languages,
you can use Unicode escape sequences in the format \uXXXX
within strings. For example the copyright character
“©” has the Unicode sequence \u00A9:
<testcase name="hasProducer_CopyrightAsUnicode"> <assertThat testDocument="unicode/unicode_producer.pdf"> <hasProducer> <!-- 'copyright' --> <matchingComplete>txt2pdf v7.3 \u00A9 SANFACE Software 2004</matchingComplete> </hasProducer> </assertThat> </testcase>
It would be too difficult to figure out the hex code for all characters of a longer text.
Therefore PDFUnit provides the small utility ConvertUnicodeToHex.
Pass the foreign text as a string to the tool, run the program and place the
generated hex code into your test. Detailed information can be found in chapter
9.2: “Convert Unicode Text into Hex Code”.
A test with a longer sequence may look like this:
<testcase name="hasSubject_Greek"> <assertThat testDocument="unicode/unicode_subject.pdf"> <hasSubject> <matchingComplete> Εργαστήριο Μηχανικής ΙΙ ΤΕΙ ΠΕΙΡΑΙΑ / Μηχανολόγοι</matchingComplete> </hasSubject> </assertThat> </testcase>
XML and XPath based tests use XML files, which might contain Unicode data, e.g. the bookmarks extracted from the following document:
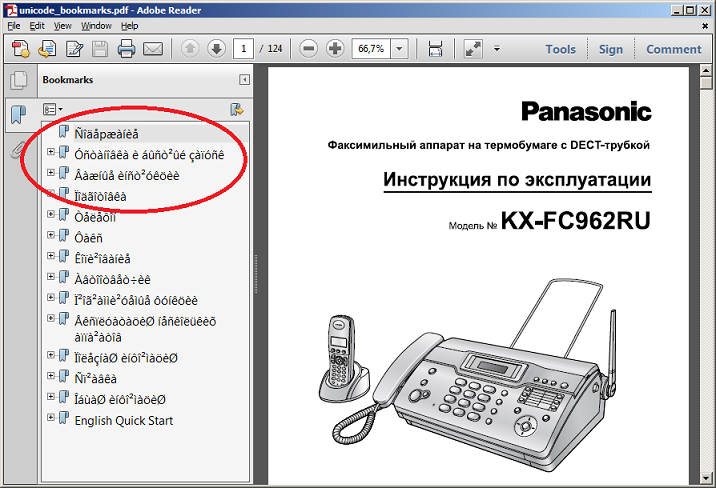
<!-- This test needs the following setting before starting ANT: set JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF-8</hasBookmarks> </assertThat> </testcase>
The chapter 8: “Using XPath” describes how to use XPath in PDFUnit tests. You can also use Unicode sequences in XPath expressions:
<testcase name="hasBookmarks_MatchingXPath"> <assertThat testDocument="unicode/unicode_bookmarks.pdf"> <hasBookmarks> <!-- The line is wrapped for printing: --> <matchingXPath expr="//Title[@Action][.='\u00D1\u00EE\u00E4 \u00E5p\u00E6\u00E0 \u00ED\u00E8\u00E5']" /> </hasBookmarks> </assertThat> </testcase>
Just like any Java program that processes files, PDFUnit depends on the environment
variable file.encoding which can be set in the following ways:
set _JAVA_OPTIONS=-Dfile.encoding=UTF8 set _JAVA_OPTIONS=-Dfile.encoding=UTF-8 java -Dfile.encoding=UTF8 java -Dfile.encoding=UTF-8
During the development of PDFUnit there were two tests which ran successfully under Eclipse, but failed with ANT due to the current encoding.
The following command did not solve the encoding problem:
// does not work for ANT: ant -Dfile.encoding=UTF-8
Instead, the property had to be set using JAVA_TOOLS_OPTIONS:
// Used when developing PDFUnit: set JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF-8
When working with XML files in Eclipse, you do not need to configure Eclipse for UTF-8, because that is the default for XML files. But the default encoding for other file types is the encoding of the file system. So it is recommended to set the encoding for the entire workspace to UTF-8:
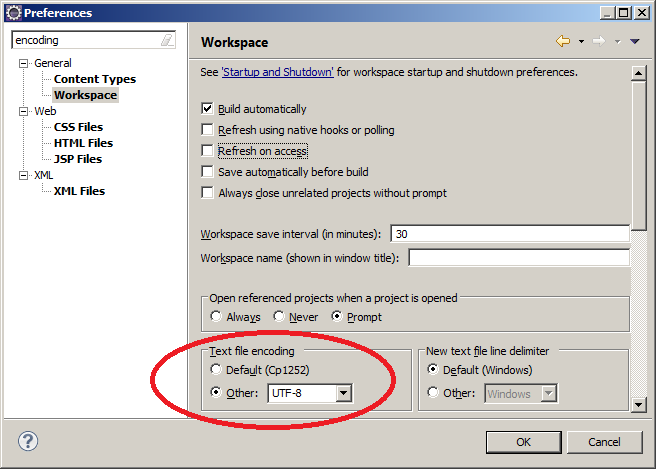
This default can be changed for each file.
If tests of Unicode content fail, the error message may be presented incorrectly in Eclipse or in a browser. Again the file encoding is responsible for this behaviour. Configuring ANT to “UTF-8” should solve all your problems. Only characters from the encoding “UTF-16” may corrupt the presentation of the error message.
The PDF document in the next example includes a layer name containing UTF-16BE characters. To show the impact of Unicode characters in error messages, the expected layer name in the test is intentionally incorrect to produce an error message:
<!-- The name of the layers consists of UTF-16BE and contains the byte order mark (BOM). The error message is not complete. It was corrupted by the internal Null-bytes. Adobe Reader® shows: "Ebene 1(4)" The used String is_: "Ebene _XXX" --> <testcase name="hasLayer_NameContainingUnicode_UTF16_ErrorIntended" errorExpected="YES" > <assertThat testDocument="unicode/unicode_layerName.pdf"> <hasLayer> <withName> <matchingComplete> \u00fe\u00ff\u0000E\u0000b\u0000e\u0000n\u0000e\u0000 \u0000_XXX </matchingComplete> </withName> </hasLayer> </assertThat> </testcase>
When the tests were executed with ANT, a browser shows the complete error
message including the trailing string þÿEbene _XXX:

A problem can occur due to a “non-breaking space”.
Because at first it looks like a normal space, the comparison with
a space fails. But when using the Unicode sequence of the “non-breaking space”
(\u00A0) the test runs successfully. Here's the test:
<!-- The content of the node value terminates with the Unicode value 'non-breaking space'. --> <testcase name="nodeValueWithUnicodeValue"> <assertThat testDocument="xfa/xfaBasicToggle.pdf"> <hasXFAData> <!-- The line is wrapped for printing: --> <withNode tag="default:p[7]" value="The code for creating the toggle behavior involves switching the border between raised and lowered, and maintaining the button's\u00A0" defaultNamespace="http://www.w3.org/1999/xhtml" /> </hasXFAData> </assertThat> </testcase>